
模型部署系列:TensorRT优化原理及模型转换的三种方式
Published:
TensorRT 是可以在 NVIDIA 各种 GPU 硬件平台下运行的一个 C++推理框架。我们利用 Pytorch、TF 或者其他框架训练好的模型,可以转化为 TensorRT 的格式,然后利用 TensorRT 推理引擎去运行我们这个模型,从而提升这个模型在英伟达 GPU 上运行的速度。速度提升的比例是比较可观的。
TensorRT 所做的优化也是基于 GPU 进行优化,适合并行计算及密集型计算。实际应用中:CenterNet 检测模型,加速 3-5 倍(Pytorch);resnet 系列的分类模型,加速 3 倍左右(Keras);GAN、分割模型系列比较大的模型,加速 7-20 倍左右(Pytorch).
TensorRT 是硬件相关的, 不同显卡其核心数量、频率、架构、设计都是不一样的,TensorRT 需要对特定的硬件进行优化,不同硬件之间的优化是不能共享的。
TensorRT 官网链接:https://developer.nvidia.com/tensorrt
TensorRT 为什么能跑那么快
TensorRT 执行五种类型的优化以提高深度学习模型的吞吐量。
算子融合(层与张量融合):简单来说就是通过融合一些计算 op 或者去掉一些多余 op 来减少数据流通次数以及显存的频繁使用来提速。
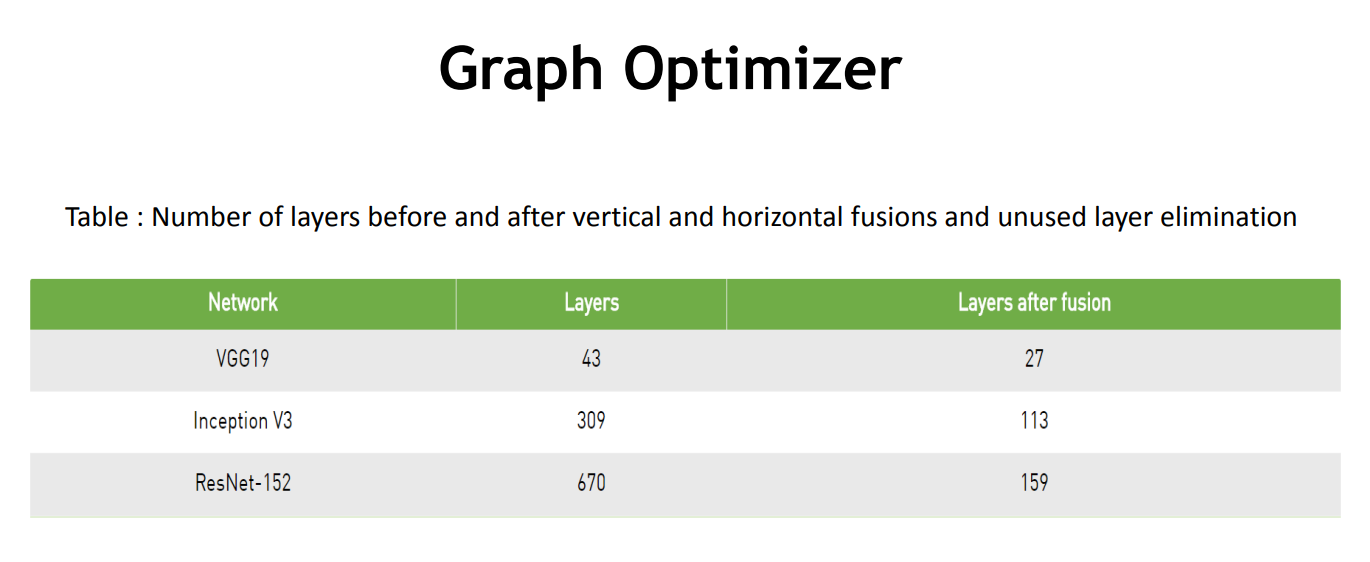
TensorRT 通过对层间的横向或纵向合并,横向合并可以把卷积、偏置和激活层合并成一个 CBR 结构,只占用一个 CUDA 核心。纵向合并可以把结构相同,但是权值不同的层合并成一个更宽的层,也只占用一个 CUDA 核心。
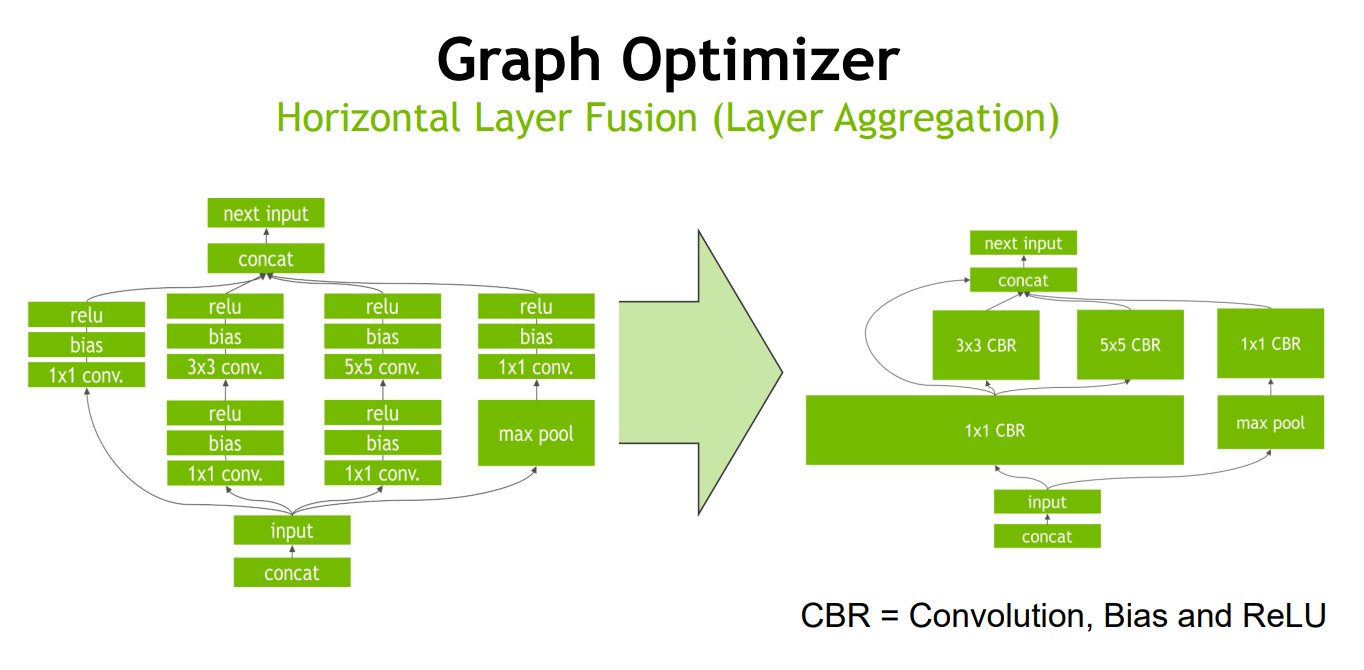
Conv + ReLU 这样的结构一般也是合并成一个 Conv 进行运算的,而这一点在全精度模型中则办不到,取决于函数是否也只是在做 clip 操作,例如 ReLU6 也有同样的性质。参考链接 5。
Concat 层的消除:对于 channel 维度的 concat 层,TensorRT 通过非拷贝方式将层输出定向到正确的内存地址来消除 concat 层,从而减少内存访存次数。
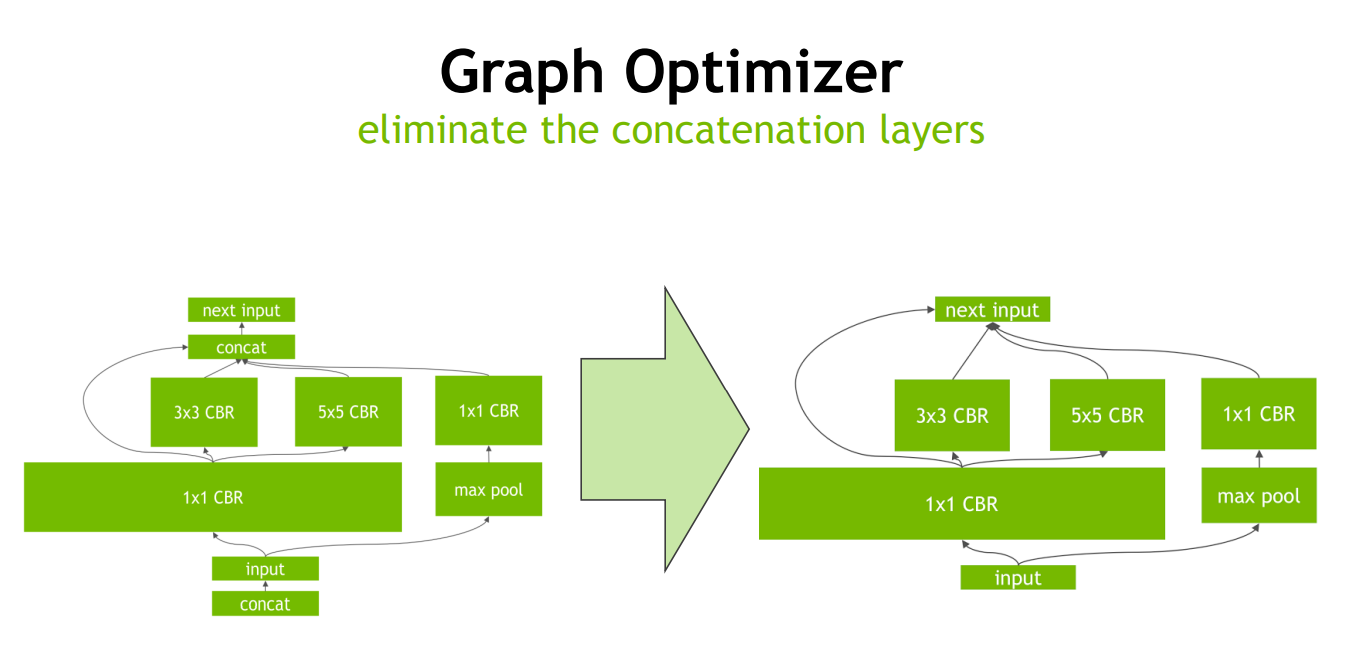
量化:量化即 IN8 量化或者 FP16 以及 TF32 等不同于常规 FP32 精度的使用,这些精度可以显著提升模型执行速度并且不会保持原先模型的精度。在转换为 FP16(较低精度)时,由于 FP16 的动态范围低于 FP32,我们的一些权重会由于溢出而缩小。使用缩放和偏置项以 INT8 精度映射这些权重。
如何获得阈值的最优值?因此,为了在 INT8 TensorRT 中表示 FP32 分布,使用 KL 散度来测量差异并将其最小化。TensorRT 使用迭代搜索而不是基于梯度下降的优化来寻找阈值。下面给出了 KL 散度的伪代码步骤

支持的融合优化,Convolution and GELU Activation,Convolution And ElementWise Operation,Shuffle and Reduce:一个没有 reshape 的 Shuffle 层,然后是一个 Reduce 层,可以融合成一个 Reduce 层。 Shuffle 层可以执行排列,但不能执行任何重塑操作。 Reduce 层必须有一组 keepDimensions 维度。SoftMax 和 TopK 可以融合成单层。 SoftMax 可能包含也可能不包含 Log 操作。
内核自动调整:根据不同的显卡构架、SM 数量、内核频率等(例如 1080TI 和 2080TI),选择不同的优化策略以及计算方式,寻找最合适当前构架的计算方式。例如,有多种方法可以执行卷积操作,但在这个选定的平台上哪一种是最优化的,TRT 会自动选择。
动态张量显存:我们都知道,显存的开辟和释放是比较耗时的,通过调整一些策略可以减少模型中这些操作的次数,从而可以减少模型运行的时间。
多流执行:使用 CUDA 中的 stream 技术,最大化实现并行操作
TensorRT 模型构建
我们使用 TensorRT 生成模型主要有两种方式:
a. 直接通过 TensorRT 的 API 逐层搭建网络;
b. 将中间表示的模型转换成 TensorRT 的模型,比如将 ONNX 模型转换成 TensorRT 模型。
0.1 直接构建
利用 TensorRT 的 API 逐层搭建网络,这一过程类似使用一般的训练框架,如使用 Pytorch 搭建网络。
0.2 IR 转换模型
直接使用 trtexec 工具,trtexec 工具有许多选项用于指定输入和输出、性能计时的迭代、允许的精度和其他选项。
第一:构建阶段的常用参数
--onnx=<model> :指定输入 ONNX 模型。
--minShapes=<shapes> , --optShapes=<shapes> , --maxShapes=<shapes> :指定用于构建引擎的输入形状的范围。仅当输入模型为 ONNX 格式时才需要。
--memPoolSize=<pool_spec> :指定策略允许使用的工作空间的最大大小,以及 DLA 将分配的每个可加载的内存池的大小。
--saveEngine=<file> :指定保存引擎的路径。
--fp16 、 --int8 、 --noTF32 、 --best :指定网络级精度。
--sparsity=[disable|enable|force] :指定是否使用支持结构化稀疏的策略。
–-best : 启用所有精度以达到最佳性能(默认 = 禁用)
–-calib= : 读取INT8校准缓存文件
第二:针对 BS=1 的模型进行转换
TensorRT-7.2.3.4/bin/trtexec \
--onnx=model/detail_1_3_64_64.onnx \
--workspace=4096 \
--saveEngine=detail_1_3_64_64.trt \
--device=0 \
--verbose
第三:动态尺度支持 NCHW 中的 N、H 以及 W,我们在转换模型的时候需要额外指定三个维度信息即可(最小、最优、最大)。
TensorRT-7.2.3.4/bin/trtexec --onnx=yolov4_-1_3_416_416_dynamic.onnx \
--minShapes=input:1x3x416x416 \
--optShapes=input:8x3x416x416 \
--maxShapes=input:8x3x416x416 \
--workspace=4096 \
--saveEngine=M-dynamic_b8_fp16.engine \
--fp16
第四:针对精度转换为 INT8 的模型,需要校准数据
batch_size = 8
batched_input = np.zeros((batch_size, 224, 224, 3))
for i in range(batch_size):
img_path = './data/img%d.JPG' % (i % 4)
img = image.load_img(img_path, target_size=(224, 224))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
batched_input[i, :] = x
batched_input = tf.constant(batched_input)
print('batched_input shape: ', batched_input.shape)
conversion_params = trt.DEFAULT_TRT_CONVERSION_PARAMS._replace(
precision_mode=trt.TrtPrecisionMode.INT8,
max_workspace_size_bytes=8000000000,
use_calibration=True)
converter = trt.TrtGraphConverterV2(
input_saved_model_dir='resnet50_saved_model',
conversion_params=conversion_params)
def calibration_input_fn():
yield (batched_input, )
converter.convert(calibration_input_fn=calibration_input_fn)
converter.save(output_saved_model_dir='resnet50_saved_model_TFTRT_INT8')
print('Done Converting to TF-TRT INT8')
0.3 IR 转换模型:代码转换
第一:从头定义网络创建 engine 的九个步骤:
step1:创建logger
step2:创建builder
step3:创建network
step4:向network中添加网络层
step5:设置并标记输出
step6:创建config并设置最大batchsize和最大工作空间
step7:创建engine
step8:序列化保存engine
step9:释放资源
第二:使用 Pytorch 实现一个只对输入做一次池化并输出的模型,其中需要使用 TensorRT 的 OnnxParser 功能,它可以将 ONNX 模型解析到 TensorRT 的网络中。实现代码如下:
import torch
import onnx
import tensorrt as trt
# network defined
class NaiveModel(torch.nn.Module):
def __init__(self):
super().__init__()
self.pool = torch.nn.MaxPool2d(2, 2)
def forward(self, x):
return self.pool(x)
# load ONNX model
onnx_model = onnx.load('model.onnx')
# create builder and network
logger = trt.Logger(trt.Logger.ERROR)
builder = trt.Builder(logger)
EXPLICIT_BATCH = 1 << (int)(
trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH)
network = builder.create_network(EXPLICIT_BATCH)
# parse onnx
parser = trt.OnnxParser(network, logger)
parser.parse(onnx_model.SerializeToString())
config = builder.create_builder_config()
config.max_workspace_size = 1<<20
profile = builder.create_optimization_profile()
profile.set_shape('input', [1,3 ,224 ,224], [1,3,224, 224], [1,3,224 ,224])
config.add_optimization_profile(profile)
# create engine
with torch.cuda.device(device):
engine = builder.build_engine(network, config)
with open('model.engine', mode='wb') as f:
f.write(bytearray(engine.serialize()))
print("generating file done!")
```
IR 转换时,如果有多 Batch、多输入、动态 shape 的需求,都可以通过多次调用 set_shape 函数进行设置。set_shape 函数接受的传参分别是:输入节点名称,可接受的最小输入尺寸,最优的输入尺寸,可接受的最大输入尺寸。一般要求这三个尺寸的大小关系为单调递增。
0.4 使用 onnx2trt 工具转 engine
#可以使用 onnx2trt 可执行文件将 ONNX 模型转换为序列化的 TensorRT 引擎
onnx2trt my_model.onnx -o my_engine.trt
#ONNX 模型也可以转换为人类可读的文本
onnx2trt my_model.onnx -t my_model.onnx.txt
#查看更多命令行参数
onnx2trt -h
#通过运行查看更多所有可用的优化过程
onnx2trt -p
TensorRT 周边配套
ONNX GraphSurgeon 可以修改我们导出的 ONNX 模型,增加或者剪掉某些节点,修改名字或者维度等;
Polygraphy 各种小工具的集合,例如比较 ONNX 和 trt 模型的精度,观察 trt 模型每层的输出等等,主要用来 debug 一些模型的信息,还是比较有用的。
TensorRT Plugin (目前只支持 C++实现),Plugin 是我们针对某个需要定制化的层或目前 TensorRT 还不支持的层进行实现、封装。TensorRT Plugin 是对网络层功能的扩展,TensorRT 官方已经预构建了一些在目标检测中经常使用的 Plugin,如:NMS、PriorBOX 等,我们可以在 TensorRT 直接使用,其他的 Plugin 则需要我们自己创建。
参考文献
- TensorRT-Index:https://docs.nvidia.com/deepl…
- API:https://docs.nvidia.com/deepl…
- ONNX GraphSurgeon: https://docs.nvidia.com/deepl…
- https://docs.nvidia.com/deepl…
- https://zhuanlan.zhihu.com/p/176982058

{kind=link}
{kind=link}
Comments