
模型部署系列:10x速度提升,Yolo检测模型稀疏化——CPU上超500FPS
Published:
YOLOv8由广受欢迎的YOLOv3和YOLOv5模型的作者 Ultralytics 开发,凭借其无锚设计将目标检测提升到了一个新的水平。YOLOv8 专为实际部署而设计,重点关注速度、延迟和经济性。
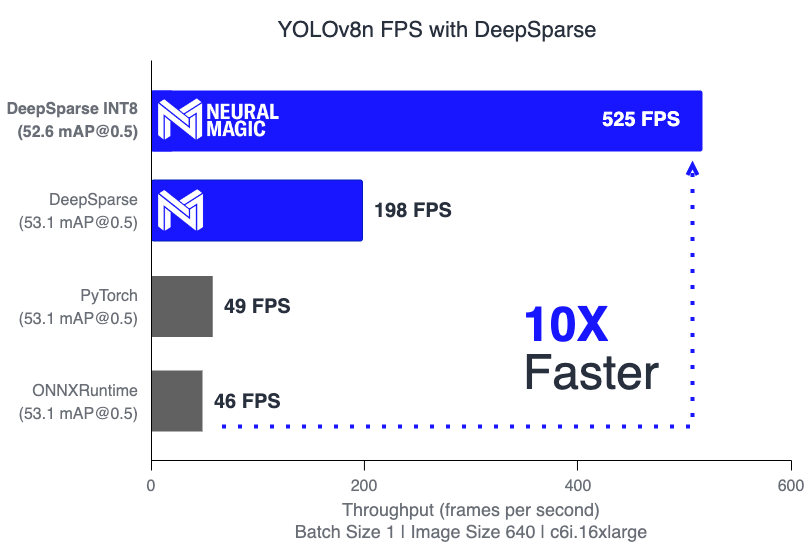
在本文中,您将了解 YOLO 的最新版本以及如何将其与 DeepSparse 一起部署以获得 CPU 上的最佳性能。我们通过在 AWS 上部署模型来说明这一点,在 YOLOv8s(小型版本)上实现 209 FPS,在 YOLOv8n(纳米版本)上实现 525 FPS,比 PyTorch 和 ONNX 运行时加速 10 倍!
有关 DeepSparse 如何通过稀疏性实现加速的详细指南,请查看 YOLOv5 with Neural Magic’s DeepSparse。
YOLOv8 用法
新的ultralytics包可以轻松地使用自定义数据训练 YOLO 模型并将其转换为 ONNX 格式以进行部署。
以下是 Python API 的示例:
from ultralytics import YOLO
# Load a model
model = YOLO("yolov8n.yaml") # build a new model from scratch
model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
# Use the model
results = model.train(data="coco128.yaml", epochs=3) # train the model
results = model.val() # evaluate model performance on the validation set
results = model("https://ultralytics.com/images/bus.jpg") # predict on an image
success = YOLO("yolov8n.pt").export(format="onnx") # export a model to ONNX format
下面是一个通过 CLI 的示例:
yolo task=detect mode=predict model=yolov8n.pt
source="https://ultralytics.com/images/bus.jpg"
使用 DeepSparse 部署 YOLOv8
对于现实应用程序中的生产部署,推理速度对于确定系统的总体成本和响应能力至关重要。DeepSparse 是一个推理运行时,专注于让 YOLOv8 等深度学习模型在 CPU 上快速运行。DeepSparse 通过推理优化的稀疏模型实现了最佳性能,它还可以有效地运行标准的现成模型。
让我们将标准 YOLOv8 模型导出到 ONNX 并在 CPU 上运行一些基准测试。
# Install packages for DeepSparse and YOLOv8
pip install deepsparse[yolov8] ultralytics
# Export YOLOv8n and YOLOv8s ONNX models
yolo task=detect mode=export model=yolov8n.pt format=onnx opset=13
yolo task=detect mode=export model=yolov8s.pt format=onnx opset=13
# Benchmark with DeepSparse!
deepsparse.benchmark yolov8n.onnx --scenario=sync --input_shapes="[1,3,640,640]"
> Throughput (items/sec): 198.3282
> Latency Mean (ms/batch): 5.0366
deepsparse.benchmark yolov8s.onnx --scenario=sync --input_shapes="[1,3,640,640]"
> Throughput (items/sec): 68.3909
> Latency Mean (ms/batch): 14.6101
DeepSparse 还提供了一些方便的实用程序,用于将模型集成到您的应用程序中。例如,您可以使用 YOLOv8 对图像或视频进行注释。带注释的文件保存在annotation-results文件夹中:
deepsparse.yolov8.annotate --source basilica.jpg --model_filepath "yolov8n.onnx # or "yolov8n_quant.onnx"

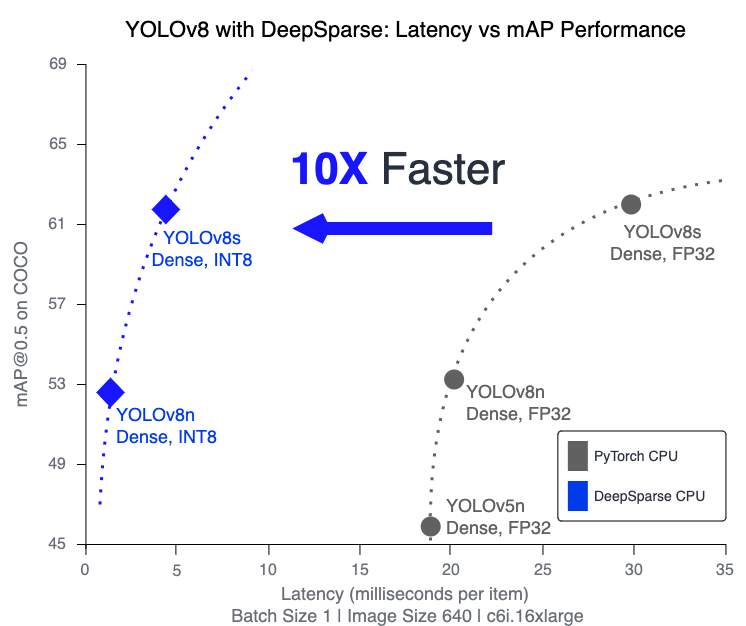
通过优化推理模型,可以进一步提升 DeepSparse 的性能。DeepSparse 的构建是为了利用通过权重修剪和量化进行优化的模型,这些技术可以在不降低准确性的情况下大幅缩减所需的计算量。通过我们的 One-Shot 优化方法(将在即将推出的 Sparsify 产品中提供),我们生成了 YOLOv8s 和 YOLOv8n ONNX 模型,这些模型已量化为 INT8,同时保持至少 99% 的原始 FP32 mAP@0.5 。这是仅使用 1024 个样本且没有反向传播即可实现的。您可以在此处下载 量化模型。
运行以下命令来测试性能:
deepsparse.benchmark yolov8n_quant.onnx --scenario=sync --input_shapes="[1,3,640,640]"
> Throughput (items/sec): 525.0226
> Latency Mean (ms/batch): 1.9047
deepsparse.benchmark yolov8s_quant.onnx --scenario=sync --input_shapes="[1,3,640,640]"
> Throughput (items/sec): 209.9472
> Latency Mean (ms/batch): 4.7631
DeepSparse在 FP32 下的速度快 4 倍,在 INT8 下的速度快 10 倍。
| Model | Size | mAPval (50-95) | mAPval (50) | Precision | Engine | Speed CPU b1(ms) | FPS CPU |
|---|---|---|---|---|---|---|---|
| YOLOv8n | 640 | 37.2 | 53.1 | FP32 | PyTorch | 20.5 | 48.78 |
| YOLOv8n | 640 | 37.2 | 53.1 | FP32 | ONNXRuntime | 21.74 | 46.00 |
| YOLOv8n | 640 | 37.2 | 53.1 | FP32 | DeepSparse | 5.74 | 198.33 |
| YOLOv8n INT8 | 640 | 36.7 | 52.6 | INT8 | DeepSparse | 1.90 | 525.02 |
| YOLOv8s | 640 | 44.6 | 62.0 | FP32 | PyTorch | 31.30 | 31.95 |
| YOLOv8s | 640 | 44.6 | 62.0 | FP32 | ONNXRuntime | 32.43 | 30.83 |
| YOLOv8s | 640 | 44.6 | 62.0 | FP32 | DeepSparse | 14.66 | 68.23 |
| YOLOv8s INT8 | 640 | 44.2 | 61.6 | INT8 | DeepSparse | 4.76 | 209.95 |

{kind=link}
{kind=link}
Comments